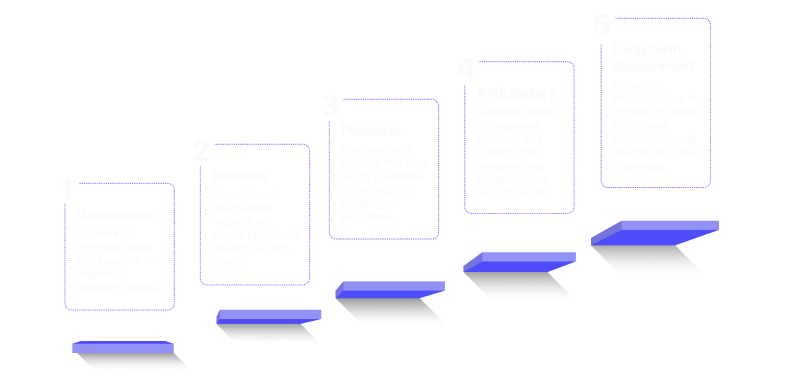
An ethical hacking assessment that simulates adversarial attacks on artificial intelligence and Large Language Model (LLM) applications. Our goal is to find model-specific security flaws like prompt injections, jailbreaks, and data leaks. All before malicious actors can exploit them to steal data or hijack connected systems.